Reference Paper
- Title: Packet-Level Traffic Prediction of Mobile Apps via Deep Learning: a “Zoom” on AI Effectiveness and Trustworthiness
- Authors: Idio Guarino, Giuseppe Aceto, Domenico Ciuonzo, Antonio Montieri, Valerio Persico and Antonio Pescapè
- Year: 2023
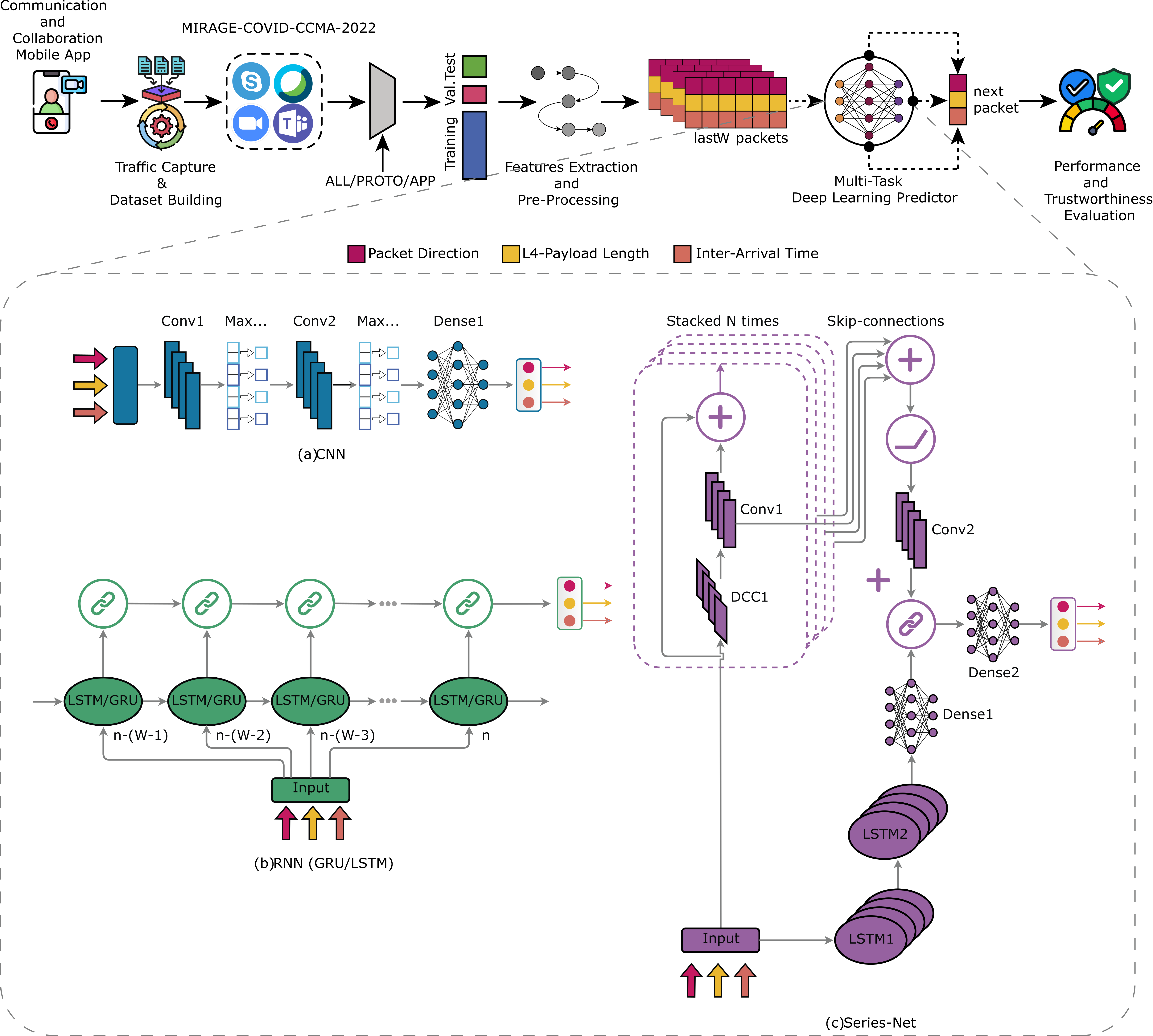
AFTER leverages Deep Learning (DL) approaches to predict network traffic generated by Communication-and-Collaboration apps (viz. CC-apps) at the finest granularity,
i.e. at the packet level.
To achieve this, it employs the widely-used bidirectional flow (viz. biflow) as traffic object for our prediction task.
A biflow embodies all the packets that share the same 5-tuple
(IPsrc, IPdst, portsrc, portdst, protocol) in both upstream and downstream directions.
Specifically, given a biflow up to its nth packet, the goal is to predict P traffic parameters associated to the (n + 1)th packet.
In this case, the desired output of our DL architecture is represented by the vector xn+1. These predictions are based on
the previous values of the same traffic parameters, which are
stored in a memory window of size W.
Then, the observations xn, . . . , xn-(W-1) are used as input to the DL architecture.
It is important to note that we construct the input using an incremental windowing approach that utilizes a sliding memory window with a unit stride.
This allows us to incrementally add samples to the window until it reaches the maximum size of W.
In cases where the prediction task has accumulated memory that is less than or equal to W, we apply left zero-padding to reach the desired window size.
This enables predictions to be made on the initial part of the biflow and/or on biflows that are shorter than W.
Furthermore, the framework leverages Multitask Architectures that simultaneously address multiple prediction tasks, with each task focusing on one of the P parameters under consideration.
More in detail, the objective is to predict three traffic parameters (P = 3) for the packets within a biflow.
These parameters are:
(i) the direction (DIR), which is a binary value indicating whether the packet is in the downstream or upstream direction;
(ii) the payload length (PL), representing the size of the transport-layer payload measured in bytes;
(iii) the inter-arrival time (IAT), which refers to the time interval between the arrival of two consecutive packets.
AFTER uses three categories of current state-of-the-art DL models, namely Convolutional (i.e. 1D-CNN), recurrent (i.e. GRU and LSTM), and a combination of both (i.e. SeriesNet) whose specific architectures are depicted in the bottom part of the above sketch.
AFTER also allows these models to be trained with different training strategies that vary based on how traffic information is grouped.
These strategies allow the models to capture traffic characteristics beyond those specific to an individual app, enabling a more comprehensive
understanding of the traffic patterns. Consequently, we examine the following three granularity levels for our analysis:
(i) Per-app level (APP): a separate model is created for each
app. This means that there is a specific predictor associated with each individual app. The models are trained using labeled traffic data that are labeled with the corresponding app information (e.g., Android package name).
(ii) Per-protocol level (PROTO): the models are designed to consider traffic based on the protocols used. However, the
models do not differentiate between individual apps within each protocol.
(iii) All apps (ALL): a single model is created to encompass all
apps. In other words, a single predictor is utilized for all apps.
The model is trained using the entire traffic dataset, without taking into account the specific information about the individual app (or protocol) that generated the traffic.
AFTER provides insights on trustworthiness of DL models via eXplainable Artificial Intelligence (XAI) techniques: it delves into the model performance and establish connections between performance and traffic characteristics. In other words, XAI strengthens the confidence in traffic prediction results and identifies areas for improvement.
Implementation
For implementing and testing the DL architectures we exploit the model provided by Keras Python API running on top of TensorFlow 2. Input data are formatted in Parquet and optimally managed via Apache PyArrow. Also, we leverage the original Deep SHAP implementation for XAI post-hoc analysis to understand input importance on the prediction of the packet-direction. Data pre- and post-processing have been performed mainly by means of Numpy and Pandas libraries. For the evaluation metrics, we use the implementation of Scikit-Learn. Finally, the graphical data representation has been obtained using Matplotlib and Seaborn.To foster the reproducibility and replicability of our analysis, we have publicly released the code of the DL architectures leveraged herein, along with pre-processed data and example usages.